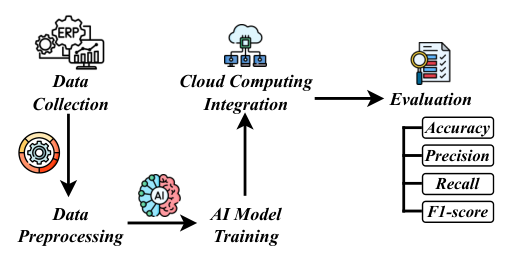
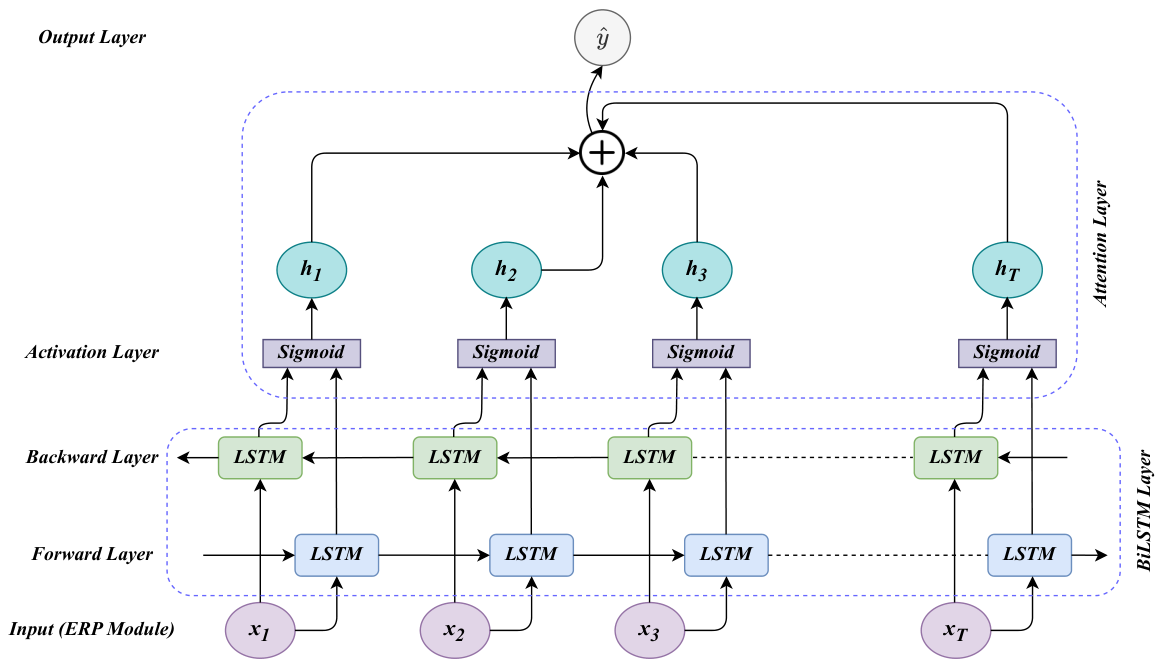
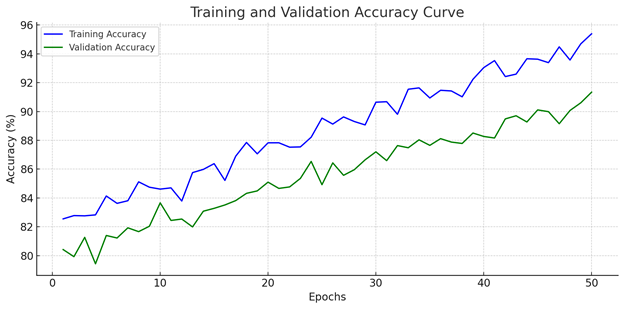
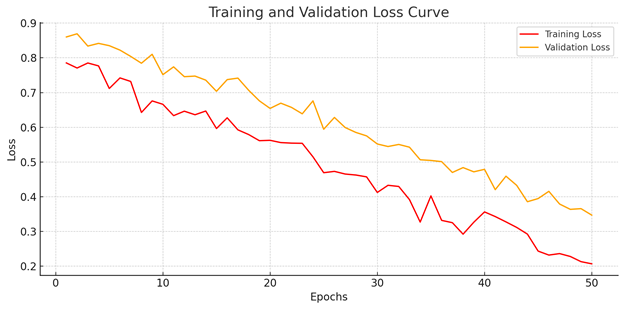
Motivation
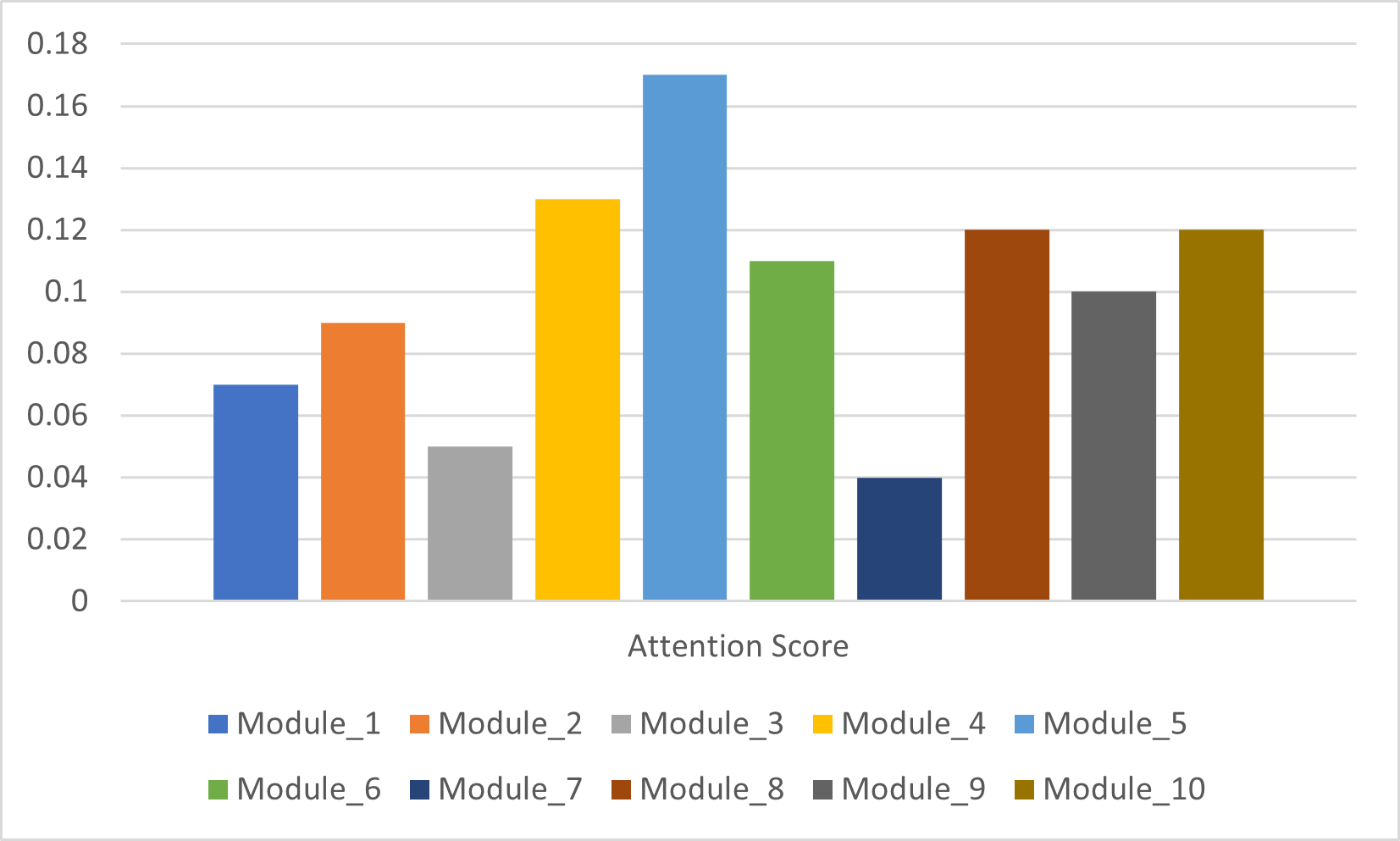
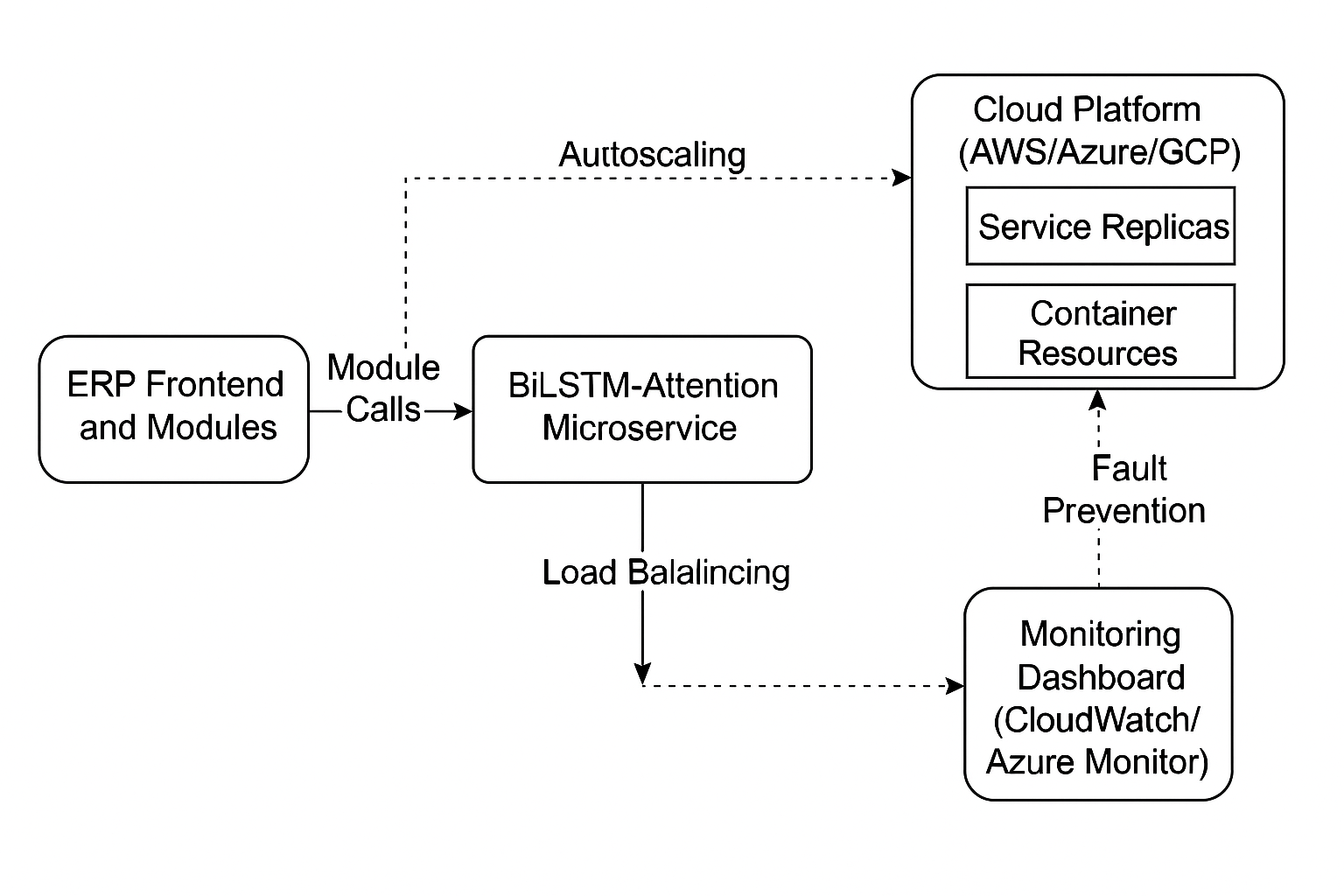
Traditional ERP systems are operationally central but often rigid, difficult to scale cleanly, and weak at producing real-time insight when module dependencies become complex.
The paper argues that AI and cloud computing together provide a better foundation: AI for predictive automation and dependency modeling, cloud for scalability and infrastructure elasticity.